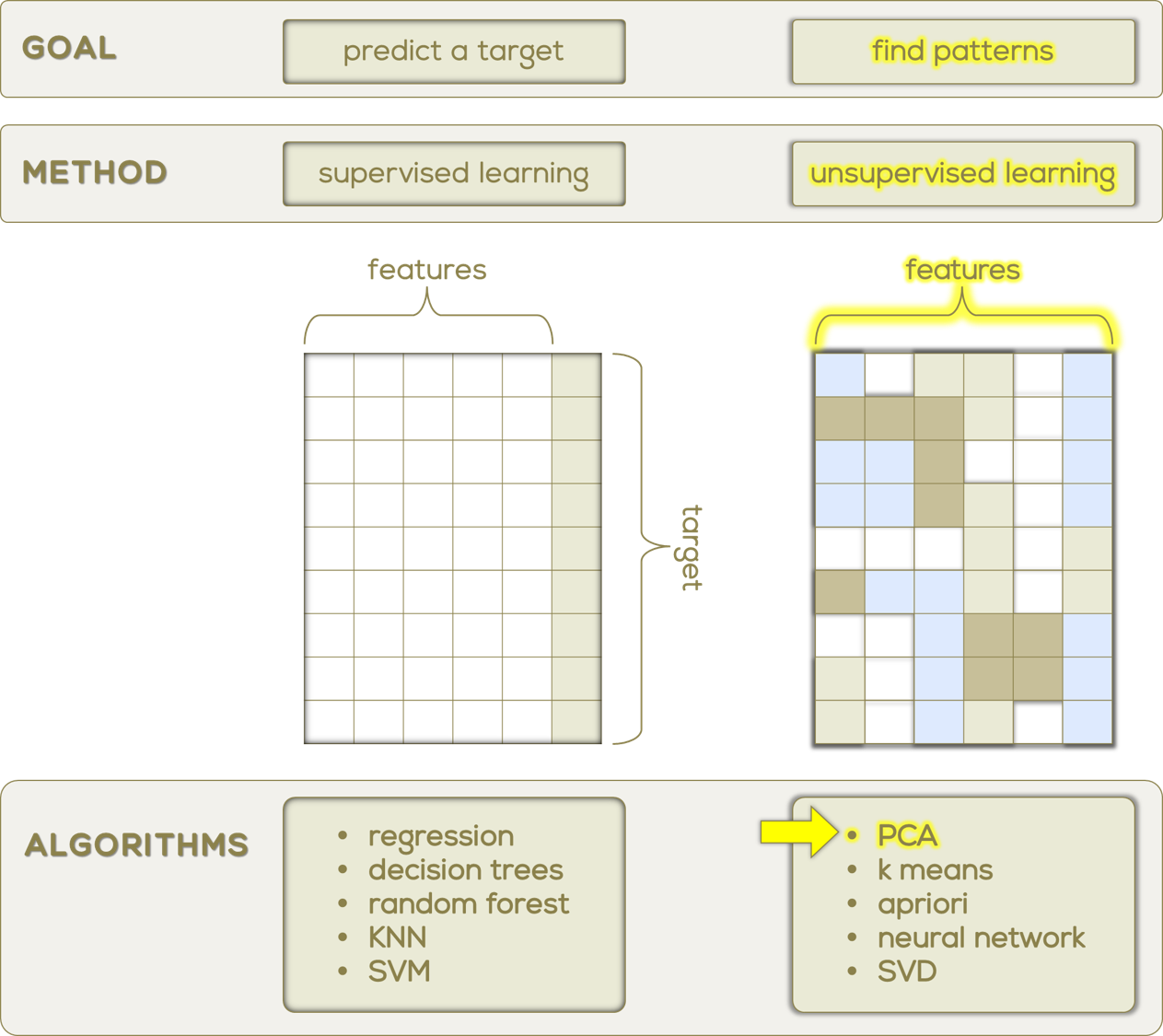
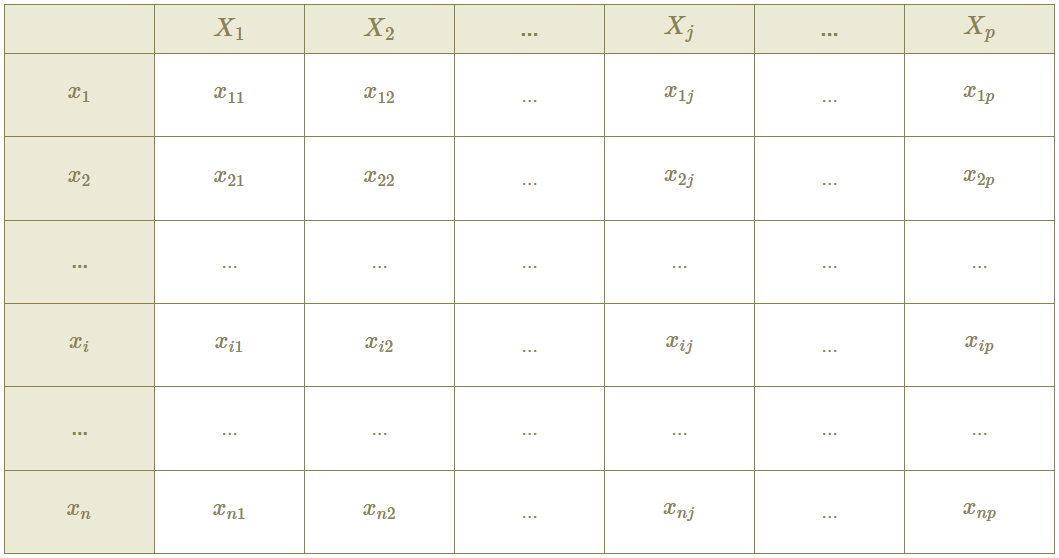
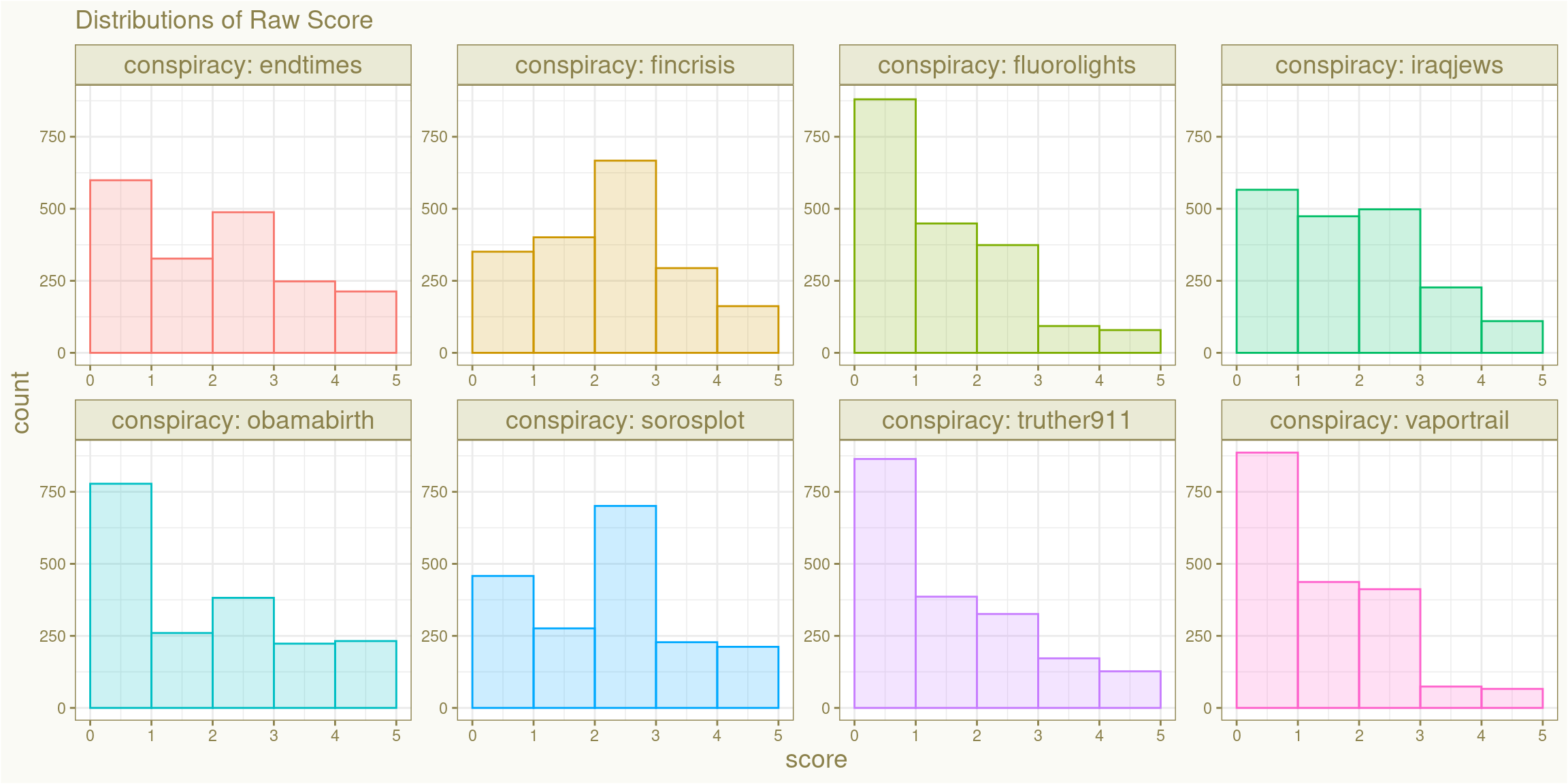
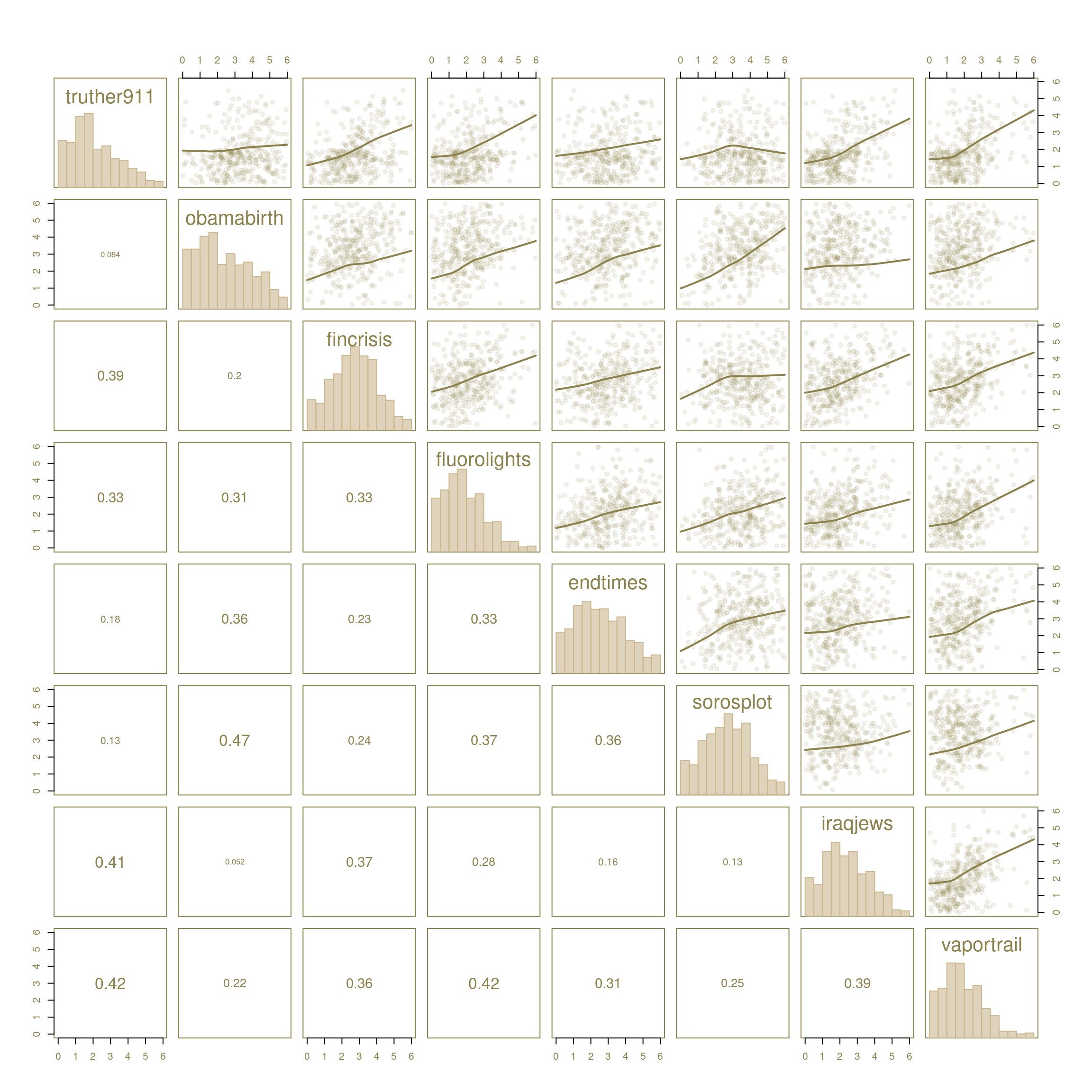
Equations
\[{\sf Standardize\ Data:}\ \ \ \ \ \ \ \ {z_{ij}}\ =\ \frac{{x_{ij}} - {\overline{x_j}}} {\sqrt{\hat{\sigma_{jj}}}}, \ \ \ \ \ where\ \ \ \ i\ =\ \{1,2,...,n\}, \ \ \ \ j\ =\ \{1,2,...,p\} \qquad(1)\]
\[{\sf Random\ Vector:}\ \ \ \ \ \ \ \ {x_i} = {({x_{i1}}, ... , {x_{ip}})}^T,\ \ \ \ \ \ \ \ \ where\ \ i\ =\ \{1,2,...,n\} \qquad(2)\]
\[{\sf Sample\ Mean\ Vector:}\ \ \ \ \ \ \ \ \hat{\mu}\ \ =\ \ \overline{x}\ \ =\ \ \frac{1}{n} \sum_{i=1}^{n} x_i \qquad(3)\]
\[{\sf Sample\ Covariance\ Vector:}\ \ \ \ \ \ \ \ \hat{\sum}\ \ =\ \ S\ \ =\ \ {(\hat{\sigma}_{ij})}_{p{\sf x}p}\ \ =\ \ \frac{1}{n-1} \sum_{i=1}^{n} {(x_i - \overline{x})(x_i - \overline{x})}^T \qquad(4)\]
\[{\sf Eigenvectors:}\ \ \ \ \ \ \ \ {\hat{a}_{k}} \qquad(5)\]
\[{\sf Eigenvalues:}\ \ \ \ \ \ \ \ {\hat{y}_{ik}}\ =\ {\hat{a}^T_{k}}(x_i\ -\ \overline{x}),\ \ \ \ \ \ \ i\ =\ \{1,2,...,n\},\ \ \ \ \ \ \ k\ =\ \{1,2,...,p\} \qquad(6)\]